


iOS 26.2: Négy újítás, amit minden nap használni fogsz
2025.12.12
| 9to5mac
Az új iOS 26.2 frissítés tele van olyan fejlesztésekkel, amelyek érezhetően kényelmesebbé teszik a mindennapi iPhone-használatot.
![]() További friss mobiltelefonos hírek! Kattintson ide!
További friss mobiltelefonos hírek! Kattintson ide!
A videóból hangot előállító MI-modellek eddig jellemzően kompromisszumokra kényszerültek: vagy a háttérzajokban voltak jók, vagy a beszédszintézisben, a kettő együtt ritkán működött igazán jól. A klasszikus video-to-sound rendszerek nehezen birkóztak meg az emberi beszéddel, míg a text-to-speech megoldások szinte vakon tapogatóztak, ha nem nyelvi hangokról volt szó. A legtöbb korábbi próbálkozás ezért különálló modellekkel, többlépcsős tanítással oldotta meg a feladatot, ami nemcsak bonyolult, de sokszor a minőség rovására is ment.
Ezen a ponton lép színre a VSSFlow, egy új mesterséges intelligencia modell, amelyet három Apple-kutató és hat, a Renmin University of China munkatársa közösen fejlesztett. A modell legnagyobb újítása, hogy egységes rendszerben képes hanghatásokat és beszédet is generálni néma videók alapján. A kutatók nemcsak technikai eleganciára törekedtek, hanem arra is, hogy a két feladat – beszéd és környezeti hang – valóban erősítse egymást a tanítás során, ne pedig versenyezzen ugyanazért a kapacitásért.
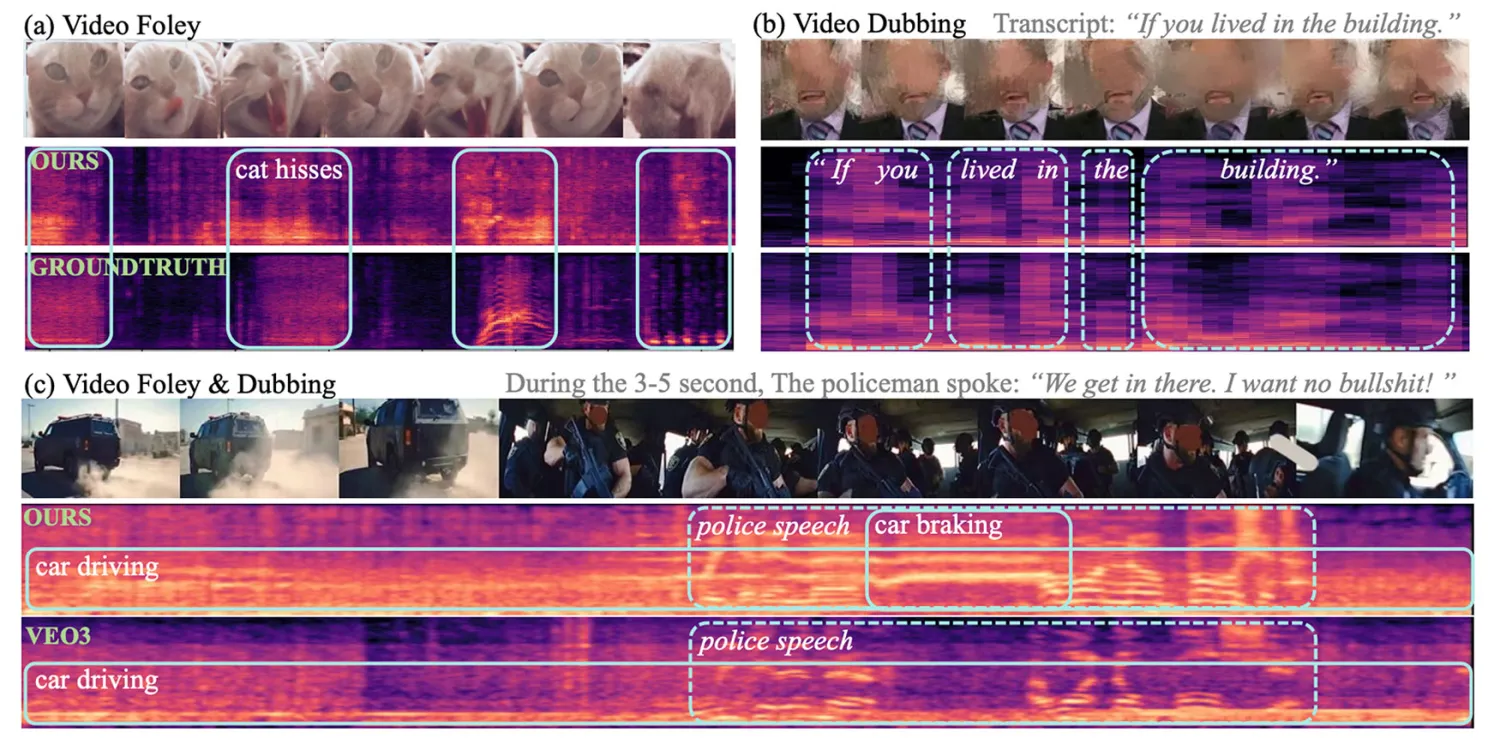
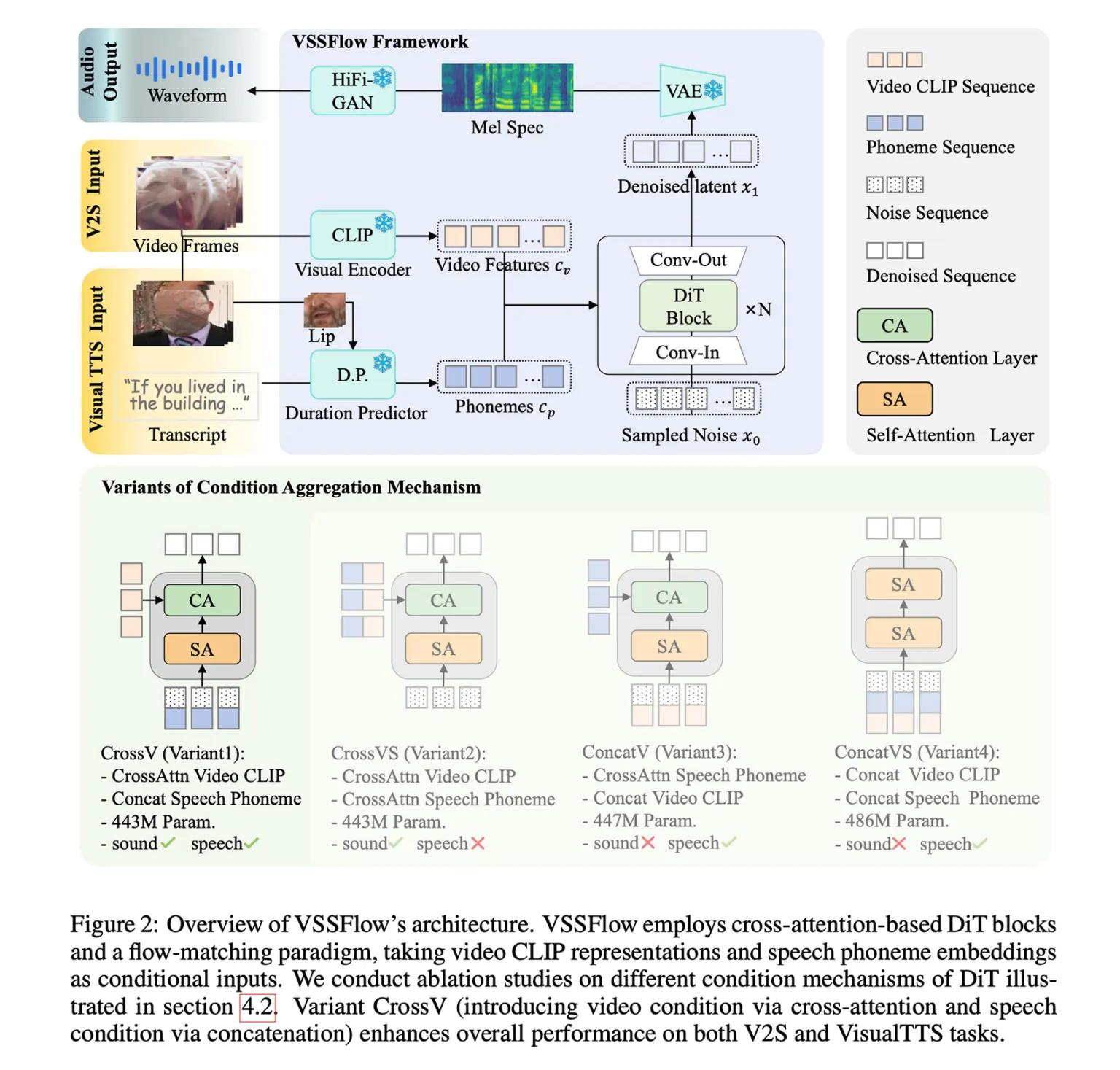
A VSSFlow architektúrája több modern generatív MI-megközelítést kombinál. A rendszer a beszédet fonéma-alapú tokenekre bontja, miközben a hangok előállítását úgynevezett flow-matching technikával tanulja meg, vagyis véletlenszerű zajból rekonstruálja fokozatosan a kívánt hangjelet. Mindez egy tízrétegű felépítésbe ágyazva működik, ahol a vizuális információk és az esetleges átiratok közvetlenül befolyásolják az audió generálását. Az eredmény egy olyan modell, amely természetes módon kezeli mind a beszédet, mind a nem beszéd jellegű hangokat.
Különösen izgalmas megállapítás, hogy a kutatók szerint a közös tanítás nem gyengíti, hanem javítja a teljesítményt mindkét területen. A modellt egyszerre tréningezték környezeti hangokkal párosított néma videókon, beszélő videókon átiratokkal, valamint klasszikus text-to-speech adatbázisokon. Ez az end-to-end megközelítés végül jobb eredményeket hozott, mint az egymástól elszigetelt, célfeladatra optimalizált megoldások.
A rendszer kezdetben még nem tudta automatikusan összekeverni a háttérzajt és a beszédet egyetlen kimenetbe, ezért a kutatók szintetikus adatokkal finomhangolták. Ezekben a példákban a beszédet és a környezeti hangokat már eleve együtt tartalmazták a minták, így a modell megtanulta, hogyan szólaljon meg a kettő egyszerre, természetes módon. A végeredmény olyan videók hangosítása lett, ahol a vizuális környezet és az elhangzó szöveg tökéletes összhangban jelenik meg.
Tesztelés során a VSSFlow több, kizárólag hanghatásokra vagy beszédre specializált modellhez képest is versenyképesnek bizonyult, sőt bizonyos mérőszámokban meg is előzte azokat, mindezt egyetlen egységes rendszerként. A kutatók bemutatóvideókat is közzétettek, amelyek jól szemléltetik a modell képességeit, beleértve az egyszerre generált beszédet és környezeti hangokat is.
Talán a legnagyobb visszhangot az váltotta ki, hogy a kutatócsoport nyílt forráskódúvá tette a VSSFlow kódját, és dolgozik a modell súlyainak publikálásán is. Emellett egy online kipróbálható demó is készülőben van. A kutatók szerint a jövő egyik legnagyobb kihívása a megfelelő minőségű, videót, beszédet és hangokat egyszerre tartalmazó adatkészletek hiánya, valamint a még hatékonyabb, tömör hang- és beszédreprezentációk kidolgozása. Ha ezek a problémák megoldódnak, a VSSFlow-hoz hasonló rendszerek alapjaiban változtathatják meg a videókészítés és az utómunka világát.

Használja a telefonja AI-alapú fotószerkesztő funkcióit (pl. tárgyak eltávolítása, Magic Eraser, háttércsere)?
![]()
Honlapunk oldalain található információk és számítások a piacon elérhető adatokon alapszanak.
Sajnos mi sem vagyunk tévedhetetlenek, és az adatközlők sem. Az esetleges pontatlanságokért valamint az adatok felhasználásból eredő károkért felelősséget nem tudunk vállalni.
A Telefonguru oldalainak másodközlése csak a tulajdonos engedélyével lehetséges!